
Has this happened to you? You open your queue on a Monday morning and find a batch of 850 purchase orders sitting in a failed state. No 997 functional acknowledgment came back from your retail partner overnight. Your fulfillment team is already asking questions.
Failed EDI transactions rarely stay contained in the integration layer. They cascade into delayed shipments, manual rework, partner chargebacks, and the kind of escalation calls nobody wants. The faster you can isolate where a transaction broke down and why, the less damage it does downstream.
This guide walks through the most common root causes of EDI failures and a practical diagnostic path experienced teams use to work through active incidents. It also covers the monitoring and governance practices that reduce how often those incidents happen in the first place.
Where Do EDI Transactions Actually Break Down?
After enough late-night incident calls, you start to notice that most failures cluster into a handful of patterns. The frustrating part is that the symptom showing in your monitoring dashboard doesn't always match the cause. A rejected 856 ASN might look like a format error on the surface.
The actual problem could be a qualifier mismatch that's been lurking in a partner's connection profile for months and only surfaced under production volume.
Knowing the failure layers and the architecture behind them helps you ask better diagnostic questions from the start, and stops you from spending two hours in the wrong place.
Sources: Stacksync, LearnEDI, EZComm
Data Format and Segment Errors
Common triggers include:
- Malformed segments
- Incorrect element qualifiers
- Missing mandatory data elements
- Values that fall outside expected ranges
These issues typically surface as validation errors in your translator logs.
An ISA header with the wrong interchange control number format, or a GS segment with a mismatched functional identifier will stop processing before the business document is even touched. When you see a generic "invalid segment" error, go to the raw EDI stream first, not the mapped output. Nine times out of ten the answer is right there.
Mapping Inconsistencies That Pass Testing but Fail in Production
Mapping errors are particularly frustrating because they often look fine in a test environment. The partner sends a small sample file, your analyst validates the map, everything clears.
Then production volume arrives with edge cases the test data didn't cover: an optional loop used differently than expected, a decimal qualifier formatted to a different precision, or a code value your implementation guide lists but your map never handles.
These failures can accumulate quietly. By the time someone flags a pattern, you already have a chargeback conversation on your hands.
Connectivity and Protocol Failures
Transfer-level disruptions that can interrupt document flow include:
- Certificate expirations
- AS2 configuration drift
- VAN routing problems
- SFTP authentication
Connectivity problems are usually easier to spot because instead of something arriving malformed, nothing arrives at all. But they can be deceptive when a connection succeeds at the transport layer and the error sits in the handshake or acknowledgment exchange.
Check your MDN receipts and transport-layer logs before assuming the message was delivered. This is where teams commonly lose an hour chasing the wrong thread.
Trading Partner Configuration Mismatches
Over time, partner setups drift. A partner might update their ISA sender ID without notification, but your system still expects the old value and rejects every inbound document as unknown.
Or a partner may move from 4010 to 5010 and your map was never updated to match. These mismatches are common after partner migrations, ERP upgrades on their side, and annual trading partner agreement renewals.
They're also easy to miss without systematic documentation of what each partner's profile actually says versus what your system expects.
System Downtime and Infrastructure Issues
Scheduled maintenance windows, unplanned outages, and resource contention on the integration server all generate transaction failures that have nothing to do with the data itself.
The challenge is distinguishing an infrastructure failure from a processing failure, especially when your monitoring tool shows the same error state for both. Always cross-reference system health logs alongside transaction logs. Skipping that step is a good way to spend an afternoon rebuilding a map that was never the problem.
A Diagnostic Path for Active EDI Failures
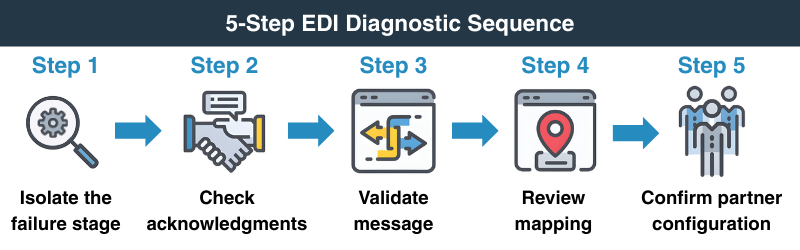
When you're in the middle of an incident, a structured sequence keeps you from jumping to conclusions.
Here are the steps an experienced integration team takes to work through a failure, which isn't always the same order as the troubleshooting guides suggest.
- Isolate the exact transaction stage. Start by identifying where processing stopped. Did the message fail at receipt, translation, mapping, or outbound delivery? Your translator's process log should give you a failure point and an error code.
Resist the urge to immediately open the map file. Confirm the failure stage first. - Check communication acknowledgments. Review functional acknowledgments (997 or 999) and technical acknowledgments (TA1) to confirm whether your message was received and accepted at the interchange level. A missing 997 tells you something different than a rejected 997.
If you're on AS2, check the MDN status. If you're using a VAN, verify the delivery confirmation on both sides of the channel. - Validate message structure against the implementation guide. Pull the raw EDI stream and compare it to the agreed implementation guide for that partner. Pay close attention to mandatory versus optional elements, loop repetition counts, and any partner-specific customizations that override the base standard.
It's worthwhile to double-check, even when you're confident the map is clean. Implementation guides sometimes get revised without fanfare. - Examine transformation rules and recent mapping changes. Review the active map version and check your change log for any recent updates. A map change that went to production without full regression testing is a common culprit, and it's often something that looked minor.
Verify that code value cross-references are current and that conditional logic in the map handles the full range of values the partner actually sends. - Confirm partner configuration details. Check the partner profile in your trading partner manager: ISA/GS identifiers, version and release numbers, envelope settings, endpoint configuration. Confirm that what's in your system reflects the partner's current setup.
When in doubt, call them. A five-minute configuration confirmation is faster than two days of log analysis, and most partners appreciate the directness.
Document each step as you go. It sounds tedious when you're under pressure, but the notes from an active incident are the most valuable institutional knowledge you'll ever produce. Undocumented fixes get rediscovered the hard way.
Why Visibility Across Your EDI Pipeline Matters
Reactive troubleshooting gets you to resolution. It doesn't shorten the window between failure and detection, and that gap is where the real cost lives. In a busy document flow, a broken transaction can sit unnoticed for hours before anyone downstream realizes orders aren't moving.
ITIC's 2024 research puts the cost of downtime above $300,000 per hour for most mid-size and large enterprises, and that's before you factor in the partner relationship damage that's harder to quantify.

Transaction monitoring platforms reduce mean time to resolution because they surface failures as they happen rather than when a fulfillment manager sends a confused email.
The most useful setups correlate three signal layers:
- Transport logs (did the message arrive?)
- Application event logs (was it processed?)
- Business document status (did it produce the expected outcome?)
Modern integration platforms make all three visible in a single environment. When they’re visible together, your EDI analysts can confirm the root cause in minutes. When they're fragmented across separate tools, you're doing archaeology.
Threshold-based alerting adds another layer of protection. Alerts on failed transaction counts, overdue acknowledgment windows, and certificate expiration dates give your team early warning before a problem turns into a partner escalation.
If your current setup doesn't cover all three signal layers, ask what you're not seeing.
How Mature Integration Teams Reduce Failure Rates Over Time
Troubleshooting faster is valuable. Needing to troubleshoot less often is better. The teams with the lowest sustained EDI error rates aren't necessarily using the most sophisticated tooling. They've standardized the things that most commonly go wrong.
Standardized Trading Partner Onboarding
Ad hoc onboarding introduces configuration variability that reliably comes back as production failures, usually six months later when you've forgotten the details.
Mature teams use a documented onboarding checklist:
- Implementation guide review
- Test transaction
- Validation across all required transaction sets
- Configuration sign-off with the partner
- A structured parallel testing period before go-live
The extra time upfront saves multiples of that time later.
Change Governance for Maps and Configurations
Version-controlled mapping repositories and a formal change review process prevent the map update that 'seemed minor' from quietly breaking a partner's production file.
At a minimum, your compliance and governance routines should include:
- A change log
- Test-file validation before any map goes to production
- A defined rollback path
- Clear ownership for post-deployment monitoring
If your team can't answer "what changed in the last 30 days and who approved it," that's a gap worth closing before the next incident.

Regression Testing Routines
Automated validation checkpoints running against a library of known-good test files catch transformation errors before they reach trading partners. Building that test library during onboarding gives you a baseline to run against every time a map changes.
It sounds like overhead until the first time it catches a mapping error that would have triggered a retailer chargeback.
Clear Ownership for Partner Communications
When a partner configuration issue surfaces, ambiguous ownership slows everything down. The EDI analyst must wait for the IT manager to engage the partner. The IT manager assumes the analyst already handled it. Meanwhile the partner's backlog is growing.
Explicit ownership, where a specific person or team owns each partner relationship including configuration changes and incident communication, eliminates that gap. It's one of the simplest structural changes a team can make, and one of the most consistently overlooked.

What Persistent EDI Failures Signal for IT Leadership
If your team spends significant time firefighting EDI failures rather than managing a stable environment, the problem is usually architectural before it's operational. Legacy translators on end-of-life infrastructure, monitoring tools that surface failures hours after they occur, and fragmented visibility across trading partner connections are architecture-level constraints.
Process discipline helps, but it doesn't fix the underlying structure.
IT directors evaluating their integration environment should ask a few direct questions:
- Does your current platform give analysts the visibility they need to diagnose failures quickly?
- Does monitoring cover all transaction stages or just transport delivery?
- Does your team have the bandwidth to handle day-to-day operations and proactive improvement at the same time, or is one consistently losing out to the other?
If you're not sure whether your environment is contributing to the pattern, download the free Legacy EDI Risk Gauge. This tool walks you through the key indicators worth paying attention to.
"Leaders shared a commitment to preparation through long-term, deliberate strategies, while non-leaders were more often focused on short-term priorities.” – Pierfrancesco Manenti, Gartner VP Analyst, Gartner Press Release
Still have questions about EDI transaction troubleshooting? See our Frequently Asked Questions below.
Still Troubleshooting the Same Failures?
If your team spends more time resolving transaction failures than preventing them, it may be time to look at your monitoring coverage and your operational model. Remedi has supported mid-market and enterprise integration environments for more than 30 years, working alongside IT teams as a co-sourcing partner to maintain transaction integrity without displacing the internal expertise you've built.
Whether you need managed EDI support, a configuration audit, or specialized staffing to fill a gap, Contact Remedi to discuss your options.

Frequently Asked Questions
What is the most common cause of failed EDI transactions? Mapping errors and trading partner configuration mismatches account for most production failures. Both are preventable with structured onboarding, version-controlled map management, and periodic partner profile reviews.
How do I find where an EDI transaction failed? Start with your translator's process log to identify the failure stage. Cross-reference functional acknowledgment status (997 or 999) and transport-layer confirmations (MDN, TA1) to confirm whether the failure is on your side, in transit, or at the partner's endpoint.
What should be in an EDI monitoring setup? At minimum: transport delivery confirmation, translation and mapping success or failure, and business document status. Alerting on acknowledgment windows and certificate expiration dates adds a proactive layer on top of that.
How can I reduce EDI error rates over time? Standardize trading partner onboarding, enforce change governance for maps and partner setups, maintain a regression test library, and assign clear ownership for each partner relationship. Most recurring failures trace back to inconsistent onboarding or undocumented map changes.
When should I consider outside support for EDI operations? If your team regularly shifts into firefighting mode rather than proactive oversight, it's worth examining your operational model. A co-sourcing arrangement can restore proactive discipline without requiring a full internal rebuild.
